[v.1.0] (05/08/2023): Post published!
Chip Huyen, a Vietnamese writer, computer scientist, and co-founder of Claypot AI, has an impressive background as a lecturer at Stanford and as a machine learning engineer at NVIDIA, Snorkel AI, Netflix, and Primer. I have been an avid reader of Chip’s books since her best-selling works in Vietnam, which inspired me to pursue my study-abroad journey in the U.S. Her latest book, published in June 2022, offers invaluable insights and practical advice on building reliable machine learning systems. After reading it for the first time, I was captivated by the depth of knowledge shared, prompting me to revisit the book multiple times to fully absorb its ideas. In this blog post, I will share my reflections and takeaways from Chip Huyen’s book after the first-read, which has greatly influenced my understanding and approach to machine learning.

Overview of ML Systems
In her book, Chip Huyen presents an overview of ML systems, defining eight main components that constitute such systems. The book adopts a “divide-and-conquer” approach, examining each component individually to facilitate a comprehensive understanding of the entire system.
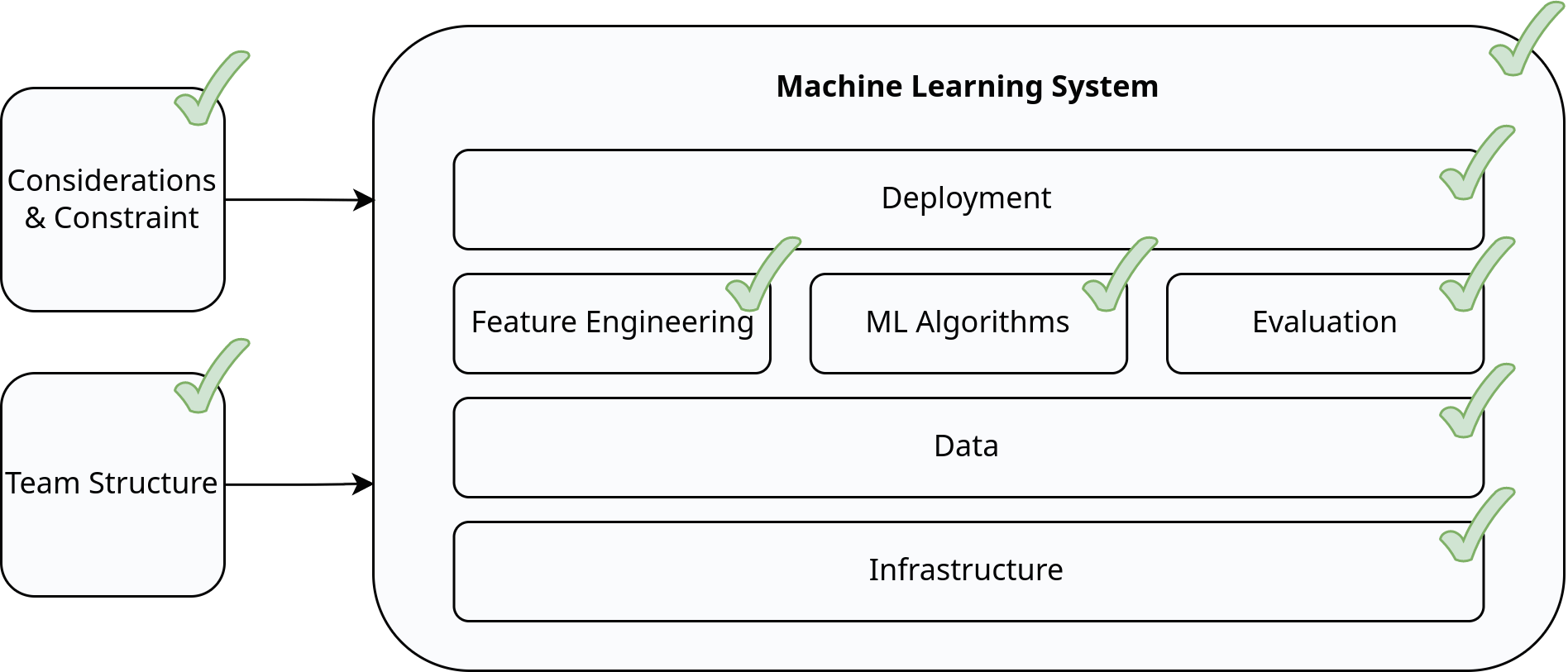
Chip’s definition of machine learning revolves around learning complex patterns from existing data and using them to make predictions on unseen data. This definition aligns with the prevalent use of supervised learning, as most ML applications involve leveraging vast amounts of user data stored in SQL databases.
So why does company integrate ML in their product? Companies integrate ML into their products due to the low cost of wrong predictions, scalability advantages, and the ability of ML models to adapt to changing patterns. For example, by identifying potential customers, displaying targeted ads, and offering timely discounts, companies like Lyft can significantly increase profits by reducing costs and attracting more long-term users.
So what is the difference between traditional software vs. ML? There are notable differences between traditional software engineering (SWE) and ML systems. In SWE, the emphasis is on modular and separated components, whereas in ML systems, code and data intertwine, making it challenging to apply SWE principles such as S.O.L.I.D or the 12-factor app to these systems.

Considerations
Before applying ML algorithms to solve a problem, it is essential to frame the problem in a way that ML can address it effectively. This involves determining the appropriate task for ML, such as binary classification, multi-class classification, or regression.
While ML metrics like accuracy or F1 score are important, most companies prioritize the ultimate goal of any project: increasing profit. This can be achieved by boosting sales, reducing costs, enhancing customer satisfaction, or increasing app engagement.
Predicting ad click-through rates and fraud detection are popular ML use cases because they directly impact business metrics. Higher click-through rates translate into increased ad revenue, while detecting and preventing fraudulent transactions saves money.
Data & Feature Engineering
Let’s look at how data can be handled in the data science perspective. For now, I will focus on sampling, labeling, and feature engineering techniques.
Data Sampling
To create train/validate/test sets, there are various data sampling techniques available. Two common approaches include random sampling and stratified sampling.
Data Labeling
When it comes to data labeling, there are several options to consider:
- Hand-labeling: This approach can be expensive, time-consuming, and may raise concerns about data privacy.
- Third-party service: Companies like Scale AI offer data labeling services and have recently secured significant contracts, such as the $250 million data labeling contract from the Department of Defense.
- Benchmark datasets: Utilizing established benchmark datasets like ImageNet and BATADAL can provide pre-labeled data for specific tasks.
- Methodological changes: If feasible, it's possible to switch from traditional supervised learning with training from scratch to alternative approaches like transfer learning, self-supervised learning, or semi-supervised learning. These methods can reduce the reliance on extensive labeled data.

Feature Engineering
The significance of feature engineering cannot be overstated in the development of ML models. Even with state-of-the-art ML architectures, performance can suffer if an inadequate set of features is used. While (deep learning) models can extract features to some extent, providing well-engineered features that enable the model to better comprehend the data can greatly benefit your application. By inputting carefully selected and curated features, you enhance the model’s ability to effectively capture and utilize relevant information.
ML Algorithms & Evaluation
Let’s see what is Chip’s tips in terms of suitable ML algorithm(s), training paradigm, and evaluation metrics.
Model Selection
Given the constraints of limited computation power and time, it is crucial to strategically choose ML models based on their advantages and disadvantages. This is where the knowledge gained from classes and academic papers becomes applicable. Benchmark datasets, such as ImageNet, SMAC, or VQA, can serve as valuable references for model selection. Additionally, factors like the number of parameters (model complexity) and interpretability can influence the choice of models. The availability of auto-selecting tools like AutoML from H2O.ai or AutoTrain from HuggingFace provides reasonable options as well.
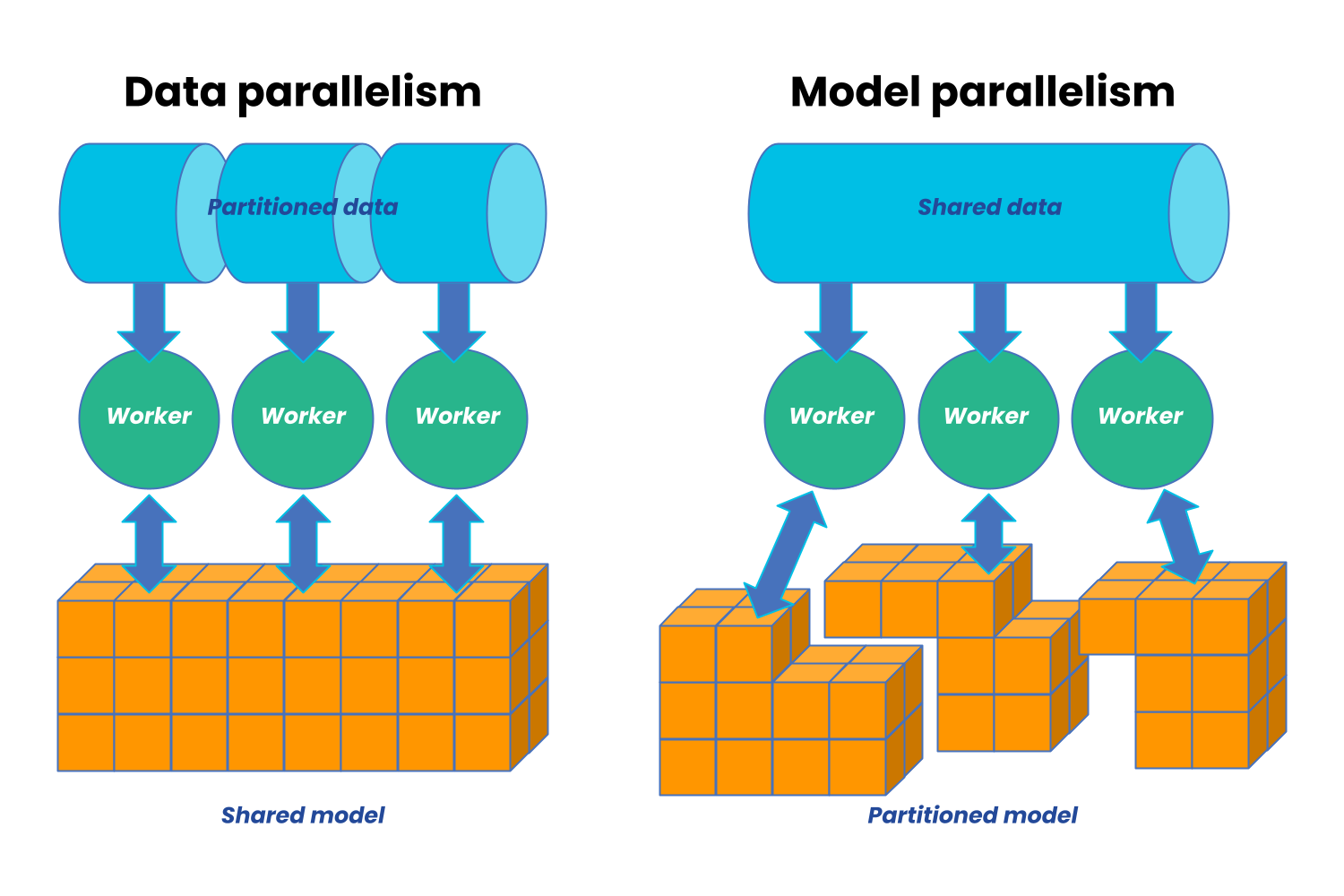
Distributed Training Paradigms
Consideration of distributed training paradigms is important when dealing with large models or datasets. Let’s examine data parallelism and model parallelism.
Data parallelism involves splitting the data across multiple machines, training the model on each machine, and accumulating gradients.
Model parallelism, on the other hand, involves training different components of the model on different machines. For instance, machine 0 handles the computation for the first two layers while machine 1 handles the next two layers. It’s important to note that “model parallelism” can be misleading because in some cases, parallel execution doesn’t occur across different parts of the model on different machines. Instead, each part is executed sequentially or consecutively.
Model Evaluation
Deploying a model involves more than simply pickling the model and using it in a Python script. There are several important aspects to consider in the deployment process.
Model Deployment
Model deployment is not simply “pickle” the model and use it on a Python script, there are several aspects to be considered.
Batch vs. Online Training
Online prediction is when predictions are generated and returned as soon as requests for these predictions arrive. For example, you enter an English sentence into Google Translate and get back its French translation immediately. When doing online prediction, requests are sent to the prediction service via RESTful APIs, that means to send back the input data, call model prediction and return the prediction result
Batch prediction is when predictions are generated periodically or whenever triggered. The predictions are stored somewhere, such as in SQL tables or an in-memory database, and retrieved as needed. For example, Netflix might generate movie recommendations for all of its users every four hours, and the precomputed recommendations are fetched and shown to users when they log on to Netflix. For example, every 4 hours, Netflix might generate movie recommendations for all of its users.
Model Compression
In scenarios where convolutional neural networks are used, model compression techniques can be applied. For example, replacing the convolutional layer with depth-wise separable convolutional layers can significantly reduce the number of parameters while maintaining performance. Similarly, classical ML algorithms like Decision Trees can be pruned to reduce model complexity.
Cloud vs. Hardware
Model deployment options include cloud deployment to platforms like AWS or GCP and hardware deployment, often referred to as edge computing. Cloud deployment offers scalability but comes with associated costs ranging from $50K to $2M per year. On the other hand, hardware deployment enables models to operate in environments with limited or unreliable internet connectivity, such as rural areas or developing countries. Edge computing also reduces network latency concerns. However, privacy risks still exist, as attackers could potentially steal user data by physically accessing the devices. Major companies like Google, Apple, and Tesla are actively developing their own chips optimized for edge computing.

In support of the semiconductor industry, the CHIPS and Science Act was signed by President Biden on August 9, 2022, aiming to strengthen the US semiconductor supply chain and foster research and development of advanced technologies within the country.
Infrastructure
The right infrastructure setup can automate processes, saving engineering time, accelerating ML application development and delivery, reducing the risk of bugs, and enabling new use cases. Conversely, a poorly implemented infrastructure can be cumbersome and costly to replace.
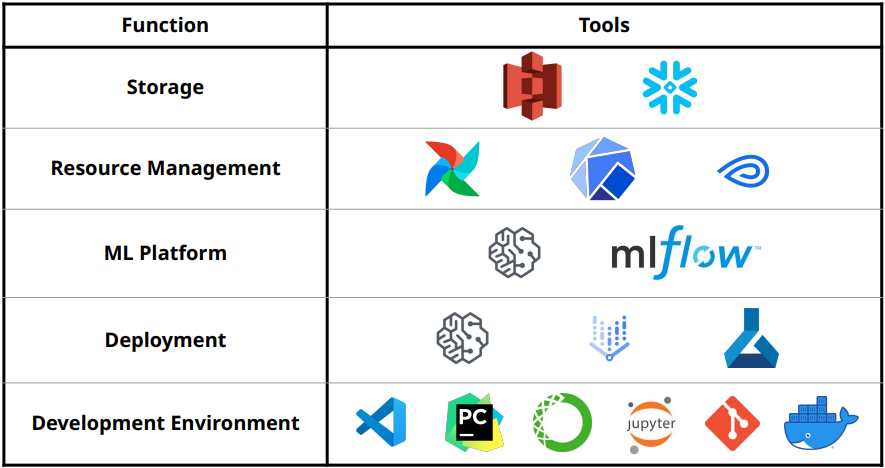
Storage: is where data is collected and stored. It can range from simple setups like hard disk drives (HDD) or solid-state drives (SSD) to more sophisticated solutions like centralized storage in platforms such as Amazon S3 or Snowflake. Data can be stored in a single location or distributed across multiple locations.
Resource Management: comprises tools to schedule and orchestrate your workloads to make the most out of your available compute resources. Popular examples in this category include Airflow, Kubeflow, and Metaflow, which help manage and allocate computing resources efficiently.
ML Platform: provides tools to aid the development of ML applications such as model stores, feature stores, and monitoring tools. Prominent examples of ML platforms include SageMaker and MLflow, which provide comprehensive capabilities for ML application development and management.
Deployment: Major cloud providers like AWS (SageMaker), GCP (Vertex AI), Azure (Azure ML), and Alibaba (Machine Learning) offer robust deployment options for ML applications. These platforms provide infrastructure and services to streamline the deployment process and ensure scalability and reliability.
Development Environment: A variety of development environments are available to facilitate ML application development. Tools such as VS Code, PyCharm, Anaconda, Jupyter Notebook, Git, and Docker are commonly used by data scientists and developers to write and manage code, create reproducible environments, and collaborate efficiently.
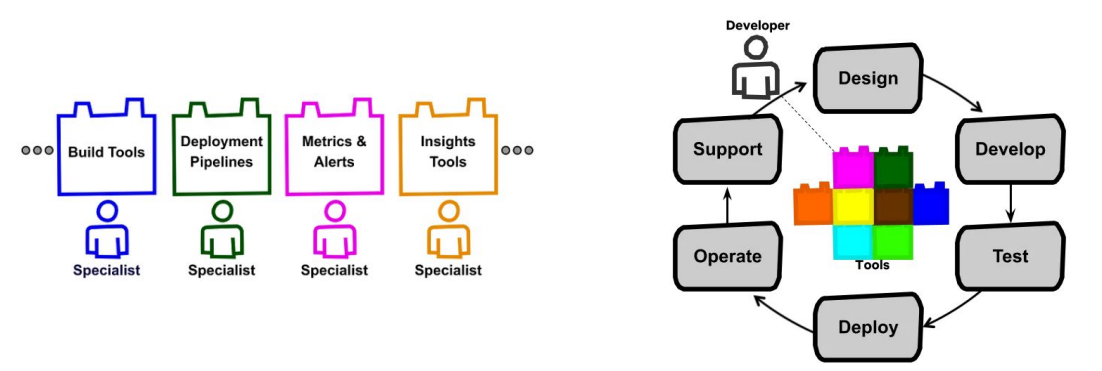
Team Structures
In many job descriptions, it is common to see Data Scientists taking ownership of the entire process, from data collection to productionization. However, Netflix has implemented an effective team structure for full-stack data scientists.
Netflix’s model involves specialists who initially own specific parts of a project. These specialists create tools and automation to streamline their respective areas. Data scientists can then leverage these tools to take ownership of their projects from end to end. As tools are developed and integrated with each other, the entire workflow is cohesive and well-integrated.
This team structure at Netflix allows for a seamless collaboration where specialists contribute their expertise to build tools, and data scientists can utilize these tools to manage the complete life cycle of their projects.
Citation
Cited as:
Nguyen, Minh. (May 2023). Designing Machine Learning Systems: A Summary https://mnguyen0226.github.io/posts/ml_systems_design/post/
Or
@article{nguyen2023mlsys,
title = "Designing Machine Learning Systems: A Summary",
author = "Nguyen, Minh",
journal = "mnguyen0226.github.io",
year = "2023",
month = "May",
url = "https://mnguyen0226.github.io/posts/ml_systems_design/post/"
}
References
[1] “Full cycle developers at Netflix,” Medium, https://netflixtechblog.com/full-cycle-developers-at-netflix-a08c31f83249 (accessed May 19, 2023).
[2] “President Biden Signs Chips and science act into law,” White & Case LLP, https://www.whitecase.com/insight-alert/president-biden-signs-chips-and-science-act-law (accessed May 19, 2023).
[3] “Cloud cost management and optimization by ANODOT,” Anodot, https://www.anodot.com/cloud-cost-management/ (accessed May 19, 2023).
[4] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” arXiv.org, https://arxiv.org/abs/1610.02357 (accessed May 19, 2023).
[5] C. Huyen, “Introduction to streaming for Data scientists,” Chip Huyen, https://huyenchip.com/2022/08/03/stream-processing-for-data-scientists.html#:~:text=Batch%20prediction%20means%20periodically%20generating,whenever%20they%20visit%20the%20website. (accessed May 19, 2023).
[6] Y. Wu et al., “Google’s Neural Machine Translation System: Bridging the gap between human and machine translation,” arXiv.org, https://arxiv.org/abs/1609.08144 (accessed May 19, 2023).
[7] “What is distributed training?,” Anyscale, https://www.anyscale.com/blog/what-is-distributed-training (accessed May 19, 2023).
[8] VQA: Visual question answering | IEEE conference publication - IEEE xplore, https://ieeexplore.ieee.org/document/7410636 (accessed May 19, 2023).
[9] B. Ellis et al., “SMACv2: An improved benchmark for cooperative multi-agent reinforcement learning,” arXiv.org, https://arxiv.org/abs/2212.07489 (accessed May 19, 2023).
[10] Practical lessons from predicting clicks on ads at facebook, https://quinonero.net/Publications/predicting-clicks-facebook.pdf (accessed May 19, 2023).
[11] “Scale AI selected by U.S. Department of Defense to accelerate government’s AI capabilities,” Business Wire, https://www.businesswire.com/news/home/20220131005304/en/Scale-AI-Selected-by-U.S.-Department-of-Defense-to-Accelerate-Government%E2%80%99s-AI-Capabilities (accessed May 19, 2023).
[12] “Deep learning with python,” Manning Publications, https://www.manning.com/books/deep-learning-with-python (accessed May 19, 2023).
[13] J. Henriksen, “Valuing lyft requires a deep look into unit economics,” Forbes, https://www.forbes.com/sites/jeffhenriksen/2019/05/17/valuing-lyft-requires-a-deep-look-into-unit-economics/?sh=17155c9a7add (accessed May 19, 2023).
[14] L. Ceci and J. 7, “Mobile app user acquisition cost 2019,” Statista, https://www.statista.com/statistics/185736/mobile-app-average-user-acquisition-cost/ (accessed May 19, 2023).
[15] C. Huyen, “Designing machine learning systems,” O’Reilly Online Learning, https://www.oreilly.com/library/view/designing-machine-learning/9781098107956/ (accessed May 19, 2023).
