[v.1.0] (03/20/2023): Post published!
During a recent interview with a Data Science Lead at a digital agriculture tech company, I had the opportunity to delve into the machine learning team’s exciting project. The team was utilizing multi-task learning (MTL) to deploy models to farming hardware, which piqued my interest and prompted me to explore this approach combined with deep learning. In particular, I wanted to investigate the effectiveness of MTL on vision transformers (ViT) and deep residual networks (ResNet-152).
In recent years, MTL has gained significant attention as a powerful technique to tackle multiple tasks simultaneously while optimizing computational resources. In computer vision, MTL has shown great potential in addressing challenges such as image segmentation, key-point detection, and edge detection. It has demonstrated remarkable improvements in data efficiency and performance on related tasks. Notably, Andrej Karpathy’s work on “Tesla Autopilot and Multi-Task Learning for Perception and Prediction” highlights how MTL enables the deployment of large models in constrained hardware settings while improving task-specific performance.
Motivated by these advancements, my goal is to thoroughly investigate the effectiveness of MTL using the ViT architecture for image classification. Additionally, I aim to compare its performance against single-task learning (STL). I focus on class and super-class classification tasks extracted from the popular CiFAR-10 and CiFAR-100 datasets to conduct this investigation. I leverage the power of Python and Tensorflow in implementing and evaluating these experiments. For the convenience of interested readers, I have made the code and results of this research available in my Github repository.
Multi-Task Learning
Multi-Task Learning (MTL) is a powerful technique that allows networks to learn multiple related tasks simultaneously instead of training separate models for each task. MTL offers better efficiency and generalization than Single-Task Learning (STL), making it popular in various fields.
Efficiency is crucial in embedded applications and deployment, where hardware limitations and cloud storage costs are considerations. MTL optimizes computational resources by jointly learning multiple tasks in a single model, improving efficiency and reducing complexity.
Generalization is essential for building artificial generalized intelligence. MTL leverages shared representations to gain a broader understanding of data patterns and correlations, enhancing adaptability to diverse scenarios.
There are two main approaches to implementing MTL: “hard-parameter” sharing and “soft-parameter” sharing. Hard-parameter sharing involves sharing some or all of the layers between tasks, enabling efficient knowledge transfer and improving model performance. In this post, I explore the application of hard-parameter sharing in image classification, specifically using vision transformers (ViT) and deep residual networks (ResNet-152).
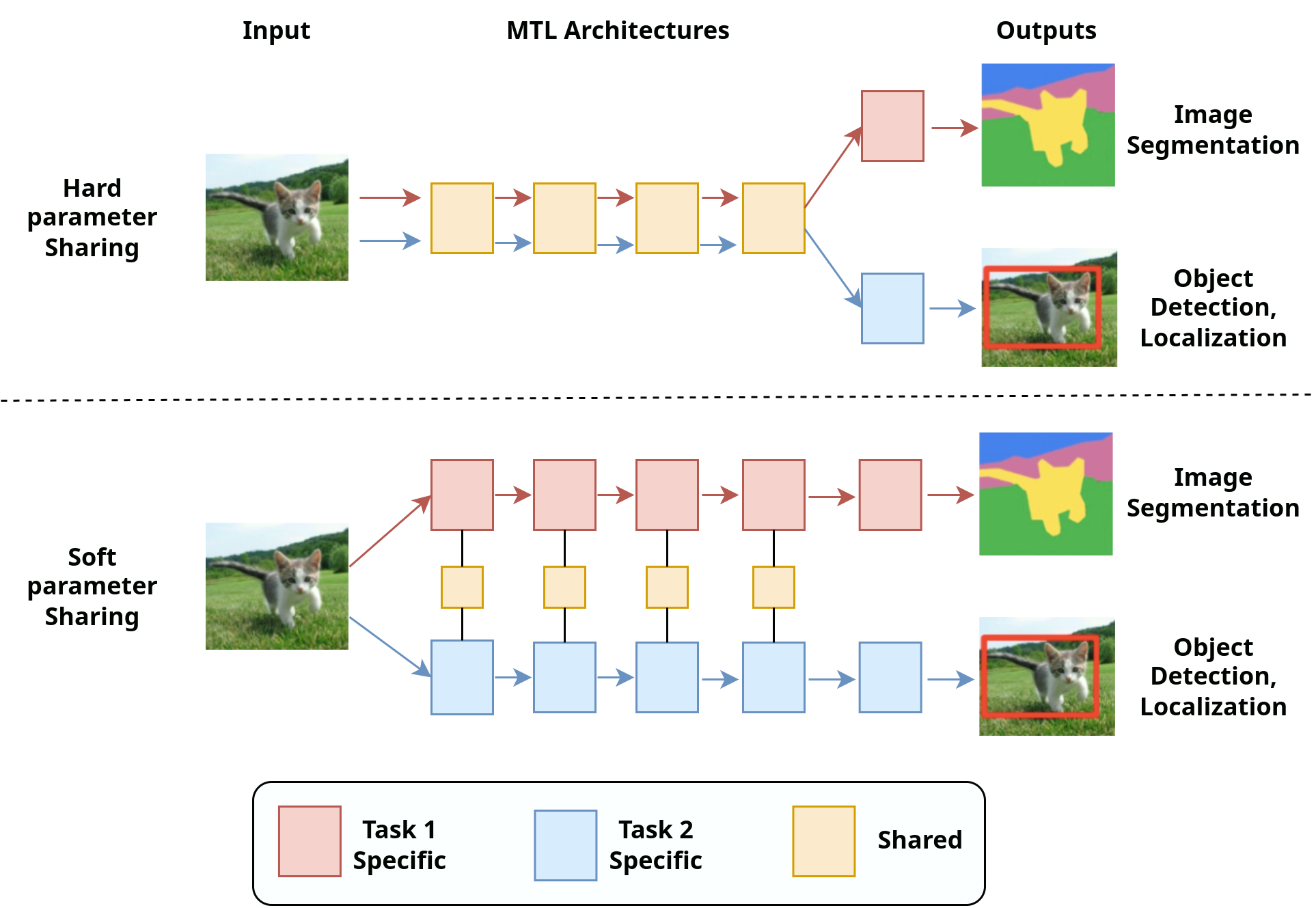
There are three research questions that I want to tackle:
- RQ1: Is an MTL ViT model superior in performance to an MTL Convolution-based model (ResNet-152)?
- RQ2: Can an MTL ViT model achieve better results than two separate STL ViT models?
- RQ3: Does an STL ViT model outperform an STL Convolution-based model (ResNet152) in terms of accuracy?
CiFAR-10 & CiFAR-100 Datasets
For the CiFAR-10 dataset, I have selected two tasks: Task 1 involves a 10-class classification, while Task 2 focuses on binary classification by categorizing the ten classes into “animal” or “vehicle” labels. For the CiFAR-100 dataset, I have identified two tasks: Task 1 encompasses a 100-class classification, and Task 2 involves a 20-superclass classification, where the 100 classes are grouped into 20 superclasses, such as aquatic mammals, fish, flowers, and food containers. The dataset details can be found on the University of Toronto’s website.

Vision Transformers (ViT)
ViT is an encoder-based transformer neural network that uses a self-attention mechanism to transform the input image into fixed-size patches and encode their positions into the input, allowing the network to capture global features and locations. In contrast, convolutional neural networks (CNN) focus on extracting local features. The ViT architecture consists of the following steps: input, linear projection, stacked encoder, multi-layer perceptron, and output labels.
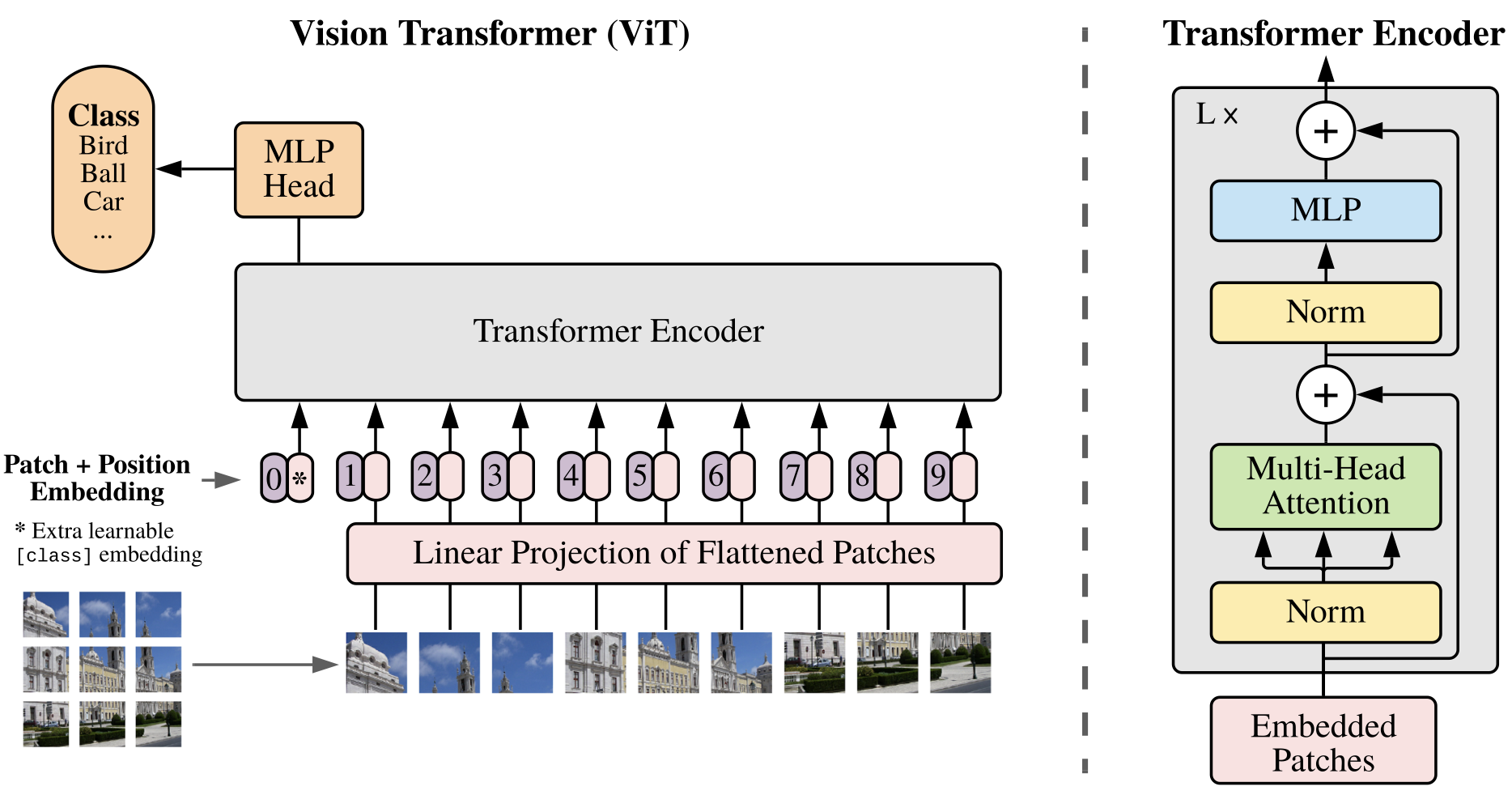
The explanation of ViT is cited from the original paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" by Dosovitskiy, Alexey, et al. The image is first converted into patches, and each patch is reshaped into a 1D vector multiplied by a learnable matrix to create a vector. Next, positional embedding is integrated as ViT is invariant to position on patches. The encoder of ViT is copied directly from the original Transformer architecture. The embedded patches are passed through a Layer Normalization to reduce training time and stabilize the training phases. Then, we pass the information through a multi-head attention network added by a skip connection to improve the performance while reducing the risk of gradient explosion or vanishing. We then pass through another Layer Normalization, Multi-layer Perceptron, and skip connection for further processing. The use of positional embedding allows ViT to behave like CNN, and this is the only inductive bias in ViT. Compared with CNN, ViT enables the network to learn the global and abstract representations of the input image, making it more robust.
Jupyter Notebooks
▪ Single-Task Learning on CiFAR-10 Dataset: A Vision Transformer Approach.
▪ Single-Task Learning on CiFAR-10 Dataset - Super-Class Classfication: A Vision Transformer Approach.
▪ Single-Task Learning on CiFAR-100 Dataset: A Vision Transformer Approach.
▪ Single-Task Learning on CiFAR-100 Dataset - Super-Class Classfication: A Vision Transformer Approach.
▪ Multi-Task Learning on CiFAR-10 Dataset: A Vision Transformer Approach.
▪ Multi-Task Learning on CiFAR-100 Dataset: A Vision Transformer Approach.
Deep Residual Network (ResNet-152)
Deep residual network-152 layers, also known as ResNet-152, is a convolutional neural network architecture designed to address the vanishing gradient problem in building deep neural networks. It was introduced in the original paper “Deep residual learning for image recognition” by He, Kaiming, et al.
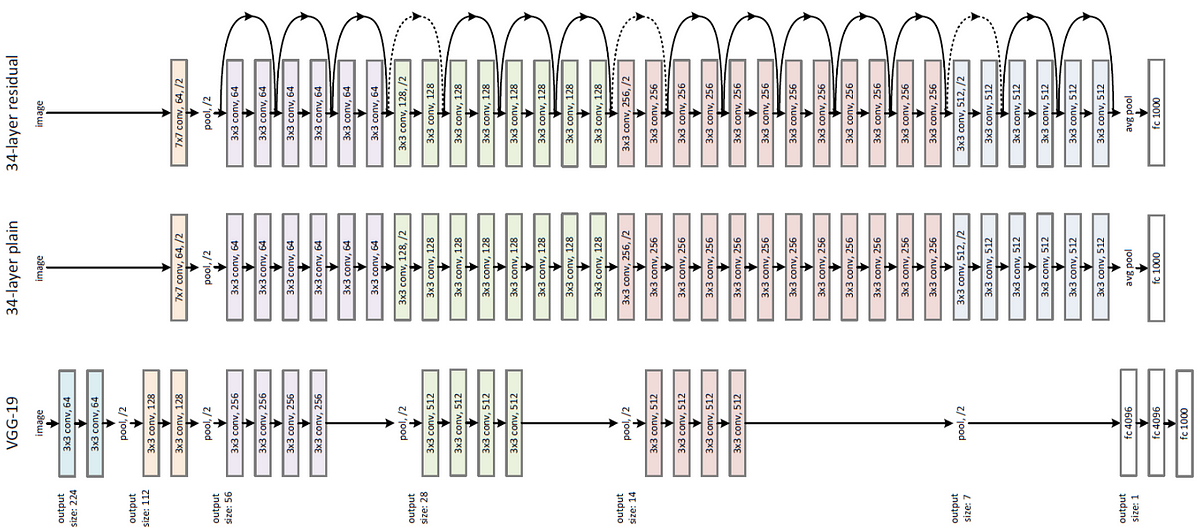
The key innovation of ResNet-152 is the residual block, which allows the network to learn residual functions that map the input to the output, rather than trying to learn the entire mapping in one shot. The residual block consists of two convolutional layers with batch normalization and ReLU activation, and a skip connection that adds the input of the block to the output of the second convolutional layer. Due to its depth, ResNet-152 can capture more complex features and achieve better performance than its shallower counterparts, such as ResNet-18, ResNet-34, and ResNet50. It has been used in various computer vision tasks, such as object detection, image classification, and image segmentation.
Jupyter Notebooks
▪ Single-Task Learning on CiFAR-10 Dataset (10 Classes): A ResNet-152 Approach.
▪ Single-Task Learning on CiFAR-10 Dataset (2 Classes): A ResNet-152 Approach.
▪ Single-Task Learning on CiFAR-100 Dataset (100 Classes): A ResNet-152 Approach.
▪ Single-Task Learning on CiFAR-100 Dataset (20 Superclasses): A ResNet-152 Approach.
▪ Mullti-task Learning on CiFAR-10 Dataset: A ResNet-152 Approach.
▪ Mullti-task Learning on CiFAR-100 Dataset: A ResNet-152 Approach.
Experimental Results
The experiment result summary can be found here.
From the experimental result, we can answer the three research questions:
RQ1: Is an MTL ViT model superior in performance to an MTL Convolution-based model (ResNet-152)?
MTL ViT outperformed MTL ResNet-152 on CiFAR-100, while MTL ResNet-152 outperformed MTL ViT on CiFAR-10 regarding testing accuracies. This result suggests that the MTL ViT is better suited for complex classification tasks, as CiFAR-100 is a more complex dataset than CiFAR-10. With more complex datasets or longer training epochs, I expect MTL ViT to outperform MTL ResNet-152 on both datasets.
RQ2: Can an MTL ViT model achieve better results than two separate STL ViT models?
MTL ViT outperformed two STL ViTs on CiFAR-10 and CiFAR-100 regarding testing accuracies. This result aligns with previous studies on benchmark datasets such as Taskonomy, Replica, and CocoDoom. The superior performance of MTL ViT is due to the sharing of the same backbone between the two tasks, which enables the network to learn more representations while significantly reducing the number of parameters.
RQ3: Does an STL ViT model outperform an STL Convolution-based model (ResNet152) in terms of accuracy?
For this question, there is no clear answer. If we use a more complex dataset or train with more epochs, we might see that ViT outperforms ResNet152 in CiFAR-10 and CiFAR-100. ViT can capture global features due to its positional embedding and attention mechanism, while ResNet-152 can capture local features due to the convolutional operation.
Citation
Cited as:
Nguyen, Minh. (March 2023). Multi-Task Learning for Image Classification https://mnguyen0226.github.io/posts/multitask_learning/post/
Or
@article{nguyen2023mtl,
title = "Multi-Task Learning for Image Classification",
author = "Nguyen, Minh",
journal = "mnguyen0226.github.io",
year = "2023",
month = "March",
url = "https://mnguyen0226.github.io/posts/multitask_learning/post/"
}
References
[1] Y. Chen, J. Yu, Y. Zhao, J. Chen, and X. Du. Task’s choice: Pruning-based feature sharing (pbfs) for multi-task learning. Entropy, 24(3):432, 2022.
[2] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016.
[3] M. Crawshaw. Multi-task learning with deep neural networks: A survey. arXiv preprint arXiv:2009.09796, 2020.
[4] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[5] Evannex. Andrej karpathy talks tesla autopilot amp; multitask learning, Aug 2019.
[6] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[7] A. Krizhevsky, V. Nair, and G. Hinton. Cifar-10 and cifar100 datasets. URl: https://www. cs. toronto. edu/kriz/cifar.html, 6(1):1, 2009.
[8] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755.Springer, 2014.
[9] A. Mahendran, H. Bilen, J. F. Henriques, and A. Vedaldi. Researchdoom and cocodoom: Learning computer vision with games. arXiv preprint arXiv:1610.02431, 2016.
[10] I. Misra, A. Shrivastava, A. Gupta, and M. Hebert. Crossstitch networks for multi-task learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3994–4003, 2016.
[11] S. Ruder. An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098, 2017.
[12] J. Straub, T. Whelan, L. Ma, Y. Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, et al. The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797, 2019.
[13] A. R. Zamir, A. Sax, W. Shen, L. J. Guibas, J. Malik, and S. Savarese. Taskonomy: Disentangling task transfer learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3712–3722, 2018.
[14] X. Zheng, B. Wu, X. Zhu, and X. Zhu. Multi-task deep learning seismic impedance inversion optimization based on homoscedastic uncertainty. Applied Sciences, 12(3):1200, 2022.
