[v.1.0] (06/15/2023): Post published!
During a recent interview for a software engineer intern position, I had an intriguing conversation with a start-up CEO. We discussed a software-system problem that presented an opportunity to gradually integrate a machine learning (ML) solution. The challenge involved a Software-as-a-Service (SaaS) platform that aimed to match buyers or customers with suitable sellers or agents. This blog chronicles my research into the fascinating profile-matching problem, with a specific focus on the matching algorithms employed.
Similar matching services can be observed in popular dating apps like Tinder and Bumble, as well as social media platforms such as LinkedIn, Facebook, Instagram, and YouTube.
In this blog I will introduce four potential ML-based solutions:
- Agent-Profile Recommendation.
- Similar Agent-Profile Listing.
- People You Might Know.
- Chatbot.
Prerequisites
Before diving into the profile-matching solutions, it’s important to establish that the following two features have already been implemented or will be addressed separately:
Buyer-profile creation:
- Account Creation: Buyers must be able to create an account by providing necessary credentials. Details on filing personal information will be discussed in later sections focusing on profile-matching algorithms.
- Robust Authentications: Implementing a secure authentication system, including features like 2-factor authentication (2FA), is crucial to maintain the integrity of buyer accounts.
- Communication Preferences: Buyers should have the option to specify their preferred communication channels and indicate their availability for booking meetings or engaging in chats with sellers.
Seller-profile creation:
- Account Creation: Sellers should have the capability to create an account using appropriate credentials. Details on filing personal information will be discussed in later sections focusing on profile-matching algorithms.
- Robust Authentications: Similar to buyers, incorporating robust authentication measures such as 2-factor authentication (2FA) helps ensure the security and trustworthiness of seller accounts.
- Availability and Profile Updates: Sellers should be able to manage their availability status and make necessary updates to their profiles or listed commodities.
Agent-Profile Recommendation
Consider the task of matching buyers and sellers as a recommendation system, where the goal is to pair each buyer with the most suitable potential seller (or vice versa).
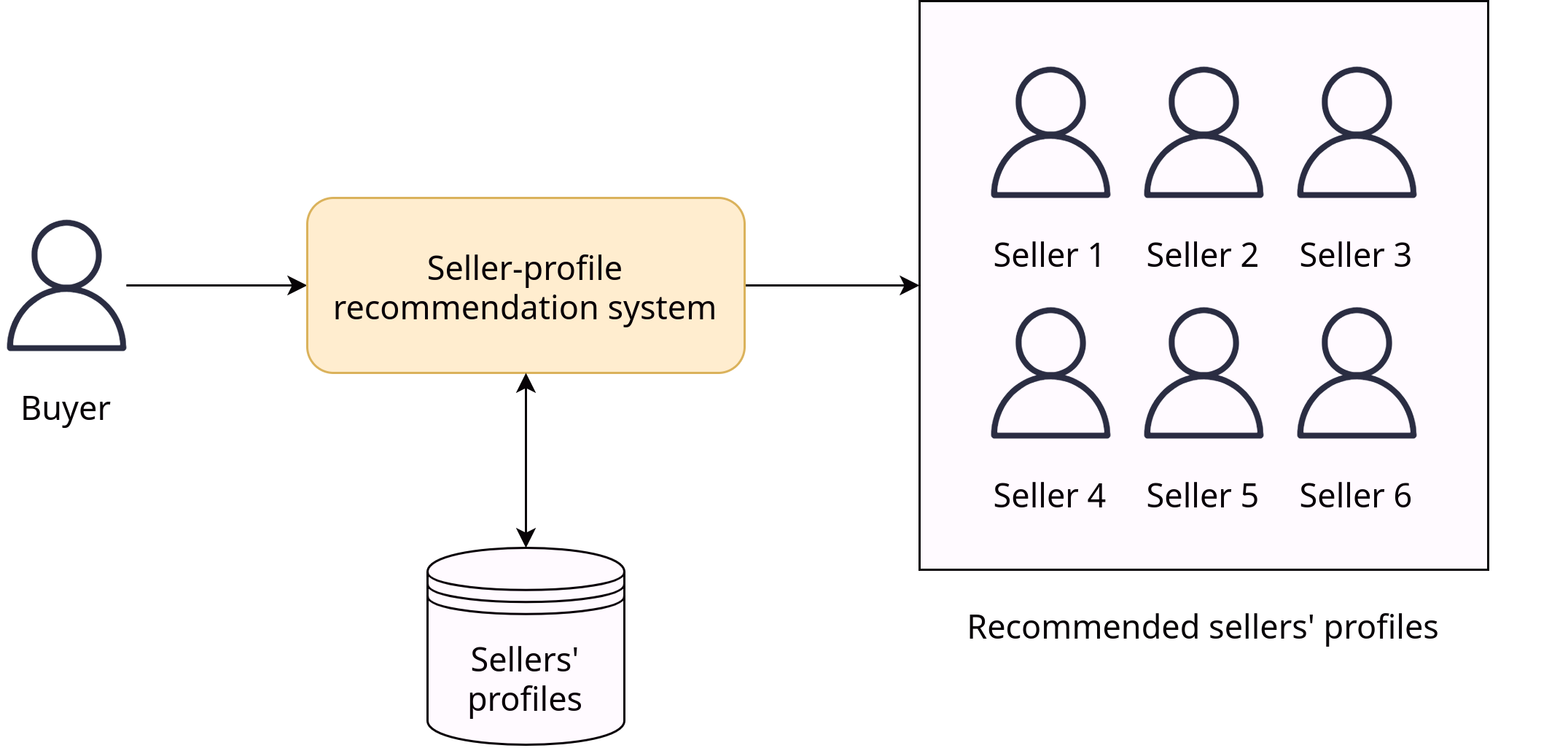
Assumptions: Initially, the buyer may not need to directly interact with the seller, but they should have access to view the seller’s profile and schedule a conversation or chat if desired. It is also assumed that the buyer has logged in, allowing us to collect data from them. Furthermore, it is important to have a substantial number of sellers’ profiles available in our database.
Framing problem as ML task: The objective is to maximize the number of relevant sellers within certain constraints, such as identifying the top 5 relevant sellers. The definition of relevance can be established by engineers or managers based on predefined rules. For instance, a seller’s profile can be considered relevant if the buyer explicitly marks it as a favorite by pressing a “star” button. Once relevance is defined, we can construct a dataset and train a model to predict the relevance score between buyers and seller(s).
Data Collection: Since both sellers and buyers need to log in, there are two approaches to collecting personal information and preference data: filtering-tabs or questionnaires. These questions can be curated by the company’s commodity specialists. Here are examples of databases for sellers, buyers, and their interactions.



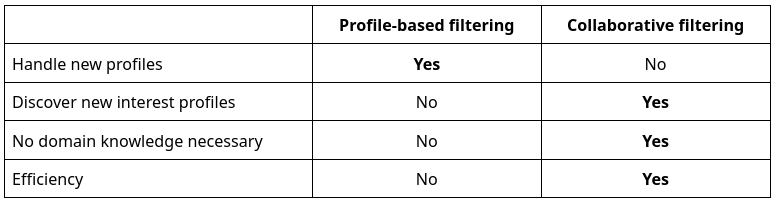
Matching Algorithms: Within the realm of agent-profile recommendation, there are three types of algorithms commonly employed: Rule-based Filtering (non-personalized), Profile-based Filtering (personalized), and Collaborative Filtering (personalized).
Rule-based Filtering
Rule-based filtering is a non-personalized approach that does not require the application of ML. In this method, the sellers’ profiles are filtered based on the buyer’s selected filtering tabs or questionnaire responses. This approach relies solely on the Seller database and can serve as a good starting point for our system.
✅ Pros:
Minimal data requirement.
▪ Rule-based filtering operates efficiently with the existing seller database without the need for extensive data collection or model training.
❌ Cons:
Lack of personalization.
▪ Generic rules used in rule-based filtering may result in recommendations that are not highly tailored to the individual preferences of buyers.
Profile-based Filtering
Profile-based filtering is a personalized algorithm that utilizes the features of sellers’ profiles to recommend new seller profiles to buyers based on their previous interactions and preferences.
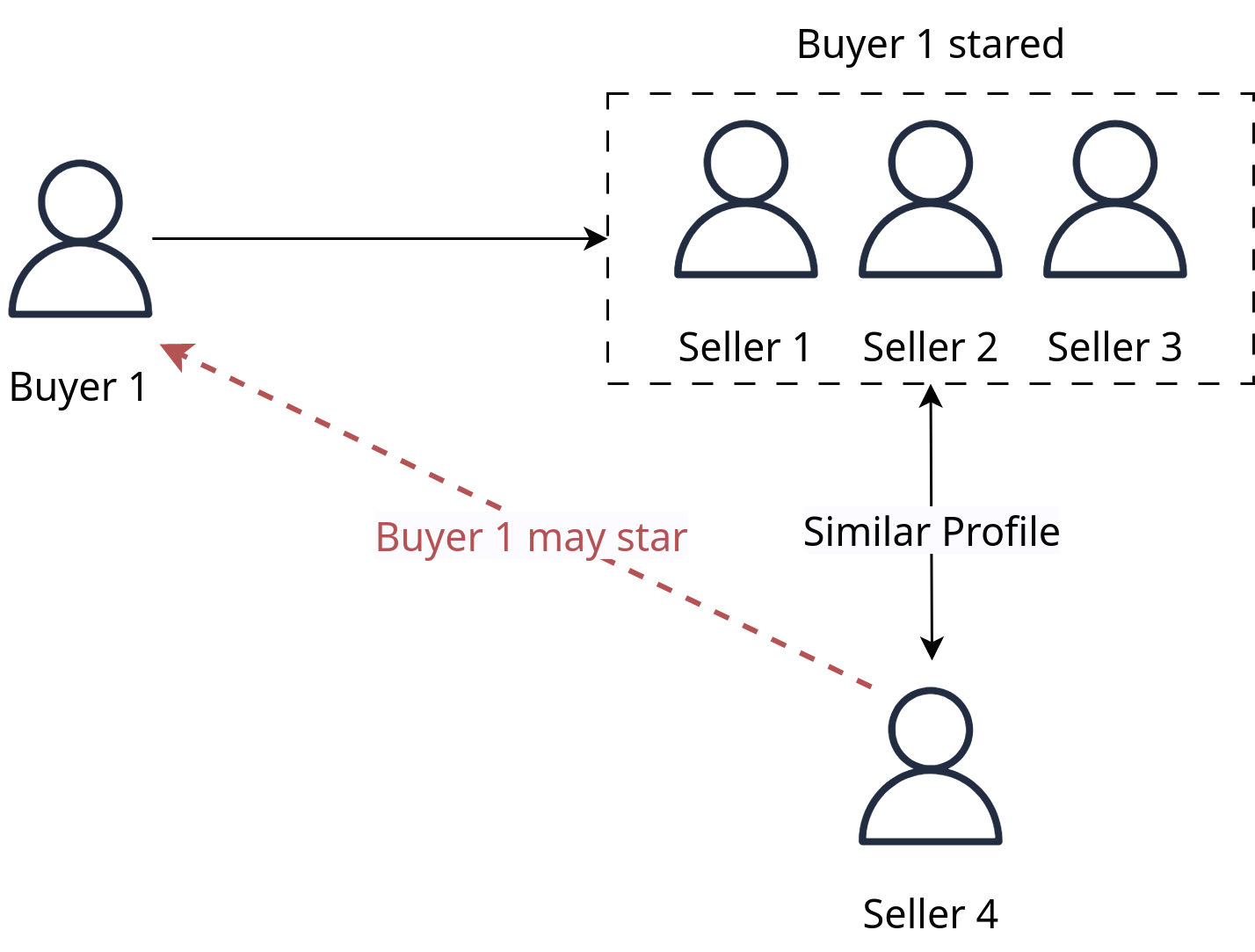
For example, in Fig. 4, we observe that Buyer 1 has engaged with Seller 1, Seller 2, and Seller 3 in the past, indicating relevance through actions such as starring the profile, engaging in conversations, providing feedback, or making purchases. Since Seller 4 has a similar profile to Seller 1, Seller 2, and Seller 3, the system will recommend Seller 4 to Buyer 1.
✅ Pros:
Recommendations of newly added seller profiles.
▪ Profile-based filtering can effectively recommend newly added seller profiles to buyers, ensuring timely exposure to relevant sellers without prior viewing.
❌ Cons:
Challenges in discovering new buyer interests.
▪ Profile-based filtering may struggle to identify a buyer's new interests that have not been previously exhibited. It relies on historical engagement data, which may overlook emerging preferences.
Collaborative Filtering
Collaborative filtering is a filtering solution that leverages the similarities between buyers to recommend new buyers’ profiles. The underlying idea is that buyers who exhibit similar behavior or preferences are likely to be interested in similar sellers.
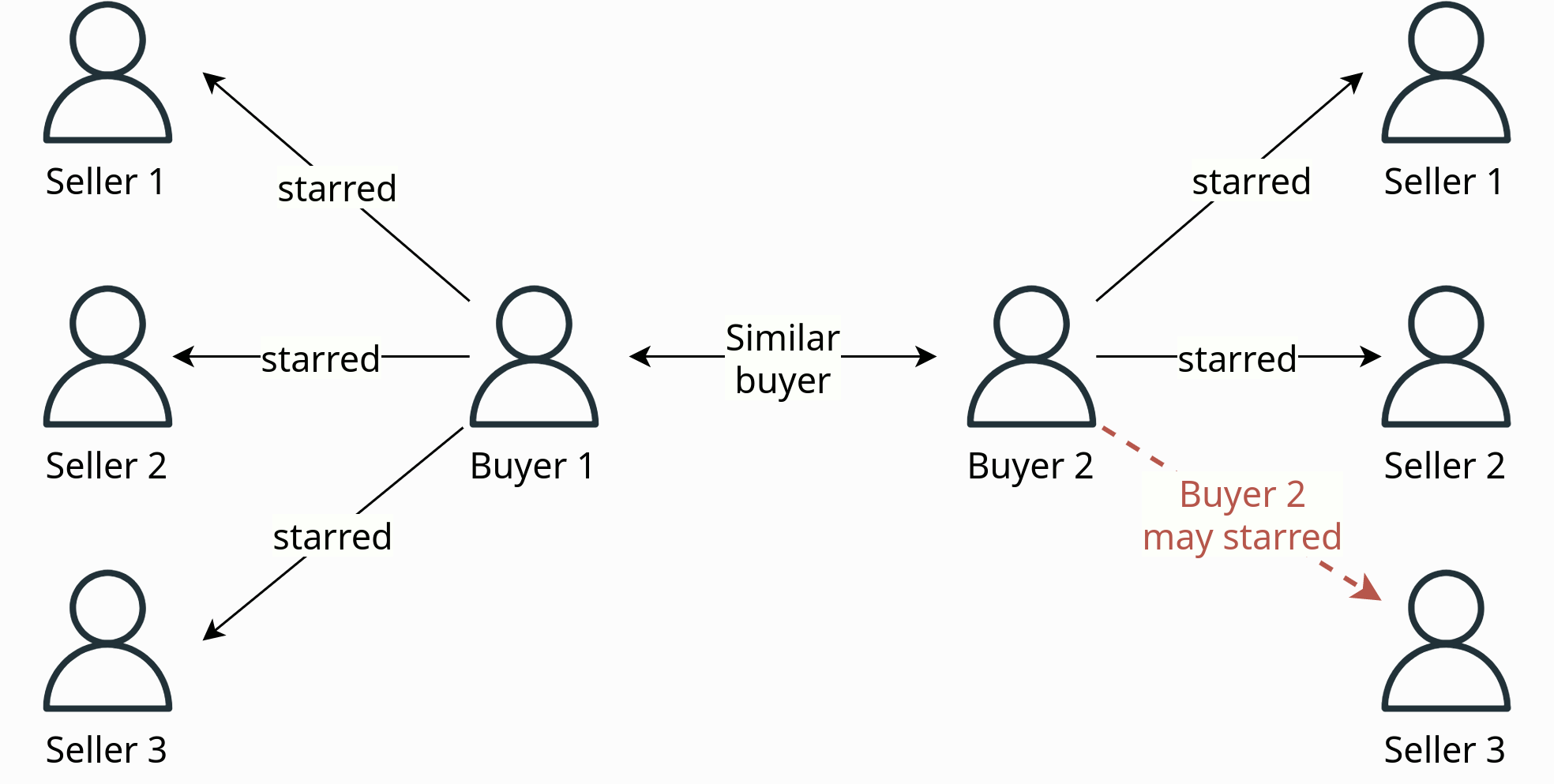
For instance, in Fig. 5, the objective is to recommend a new seller’s profile to Buyer 2. To achieve this, we first identify a similar buyer to Buyer 2 based on their previous interactions, such as Buyer 1. Next, we identify a seller’s profile, in this case, Seller 3, which Buyer 1 has engaged with but Buyer 2 has not yet seen. We then recommend Seller 3 to Buyer 2.
The main difference between collaborative filtering and profile-based filtering is that collaborative filtering does not rely on the features of sellers’ profiles. Instead, it exclusively relies on the historical interactions of buyers to make recommendations.
✅ Pros:
No domain knowledge required.
▪ Collaborative filtering does not rely on sellers' profiles, resulting in lower computational requirements and reducing the need for extensive domain knowledge.
❌ Cons:
Accuracy issues with few seller profiles.
▪ In the case of a limited number of seller profiles, the system may struggle to provide accurate recommendations, known as the cold-start problem .
Inability to handle niche interests.
▪ Collaborative filtering, based on similar buyers, may have difficulty accommodating niche interests with limited data, potentially overlooking unique preferences.
Similar Agent-Profile Listing
In our SaaS platform, we can incorporate a feature that presents a list of “similar sellers’ profiles” to the buyer after they have clicked on a specific seller’s profile.

Assumptions: The input for this feature is the list of sellers’ profiles that the buyer is currently viewing, which can be obtained through manual filtering or selection via clicks. The desired output is a ranked list of similar listings that the buyer is likely to click on next. This system can cater to both logged-in (identified) and non-logged-in (anonymous) buyers.
Framing problem as ML task: We observe that the sequence of listings that a buyer clicks on often shares common characteristics, such as sellers located in the same city or offering similar commodities within an acceptable price range. Leveraging this observation, we define the ML objective as accurately predicting the list of sellers’ profiles that the buyer is likely to click on next.
Data Collection: For logged-in users, personal information and preference data can be collected through filtering-tabs or questionnaires. These data collection methods can be curated by the company’s commodity specialists. In the case of anonymous users, we can utilize the ELK (ElasticSearch, Kibana, Logstash) stack and the Mozilla Interaction Observer API to capture users’ engagement with the web app. This stack has been utilized by companies like Facebook and Netflix for their algorithms, analyzing user scroll feed and recommending content based on scroll activity. Software companies like Amplitude offer similar services through their Amplitude APIs, enabling developers to create data analytic dashboards that showcase users’ web app engagement levels. Here are examples of seller, buyer, and interaction databases that can be utilized for data analysis and model training.



Matching Algorithm: Rather than relying solely on the buyer’s historical interactions to understand their long-term interests, our approach for profile recommendations focuses on the buyer’s recently viewed listings. This approach is known as a session-based recommendation system. The objective is to predict the next profile that the buyer is likely to click on, based on the sequence of sellers’ profiles they have recently browsed. By prioritizing the user’s most recent interactions, we aim to provide more accurate and timely recommendations, tailored to their immediate preferences.
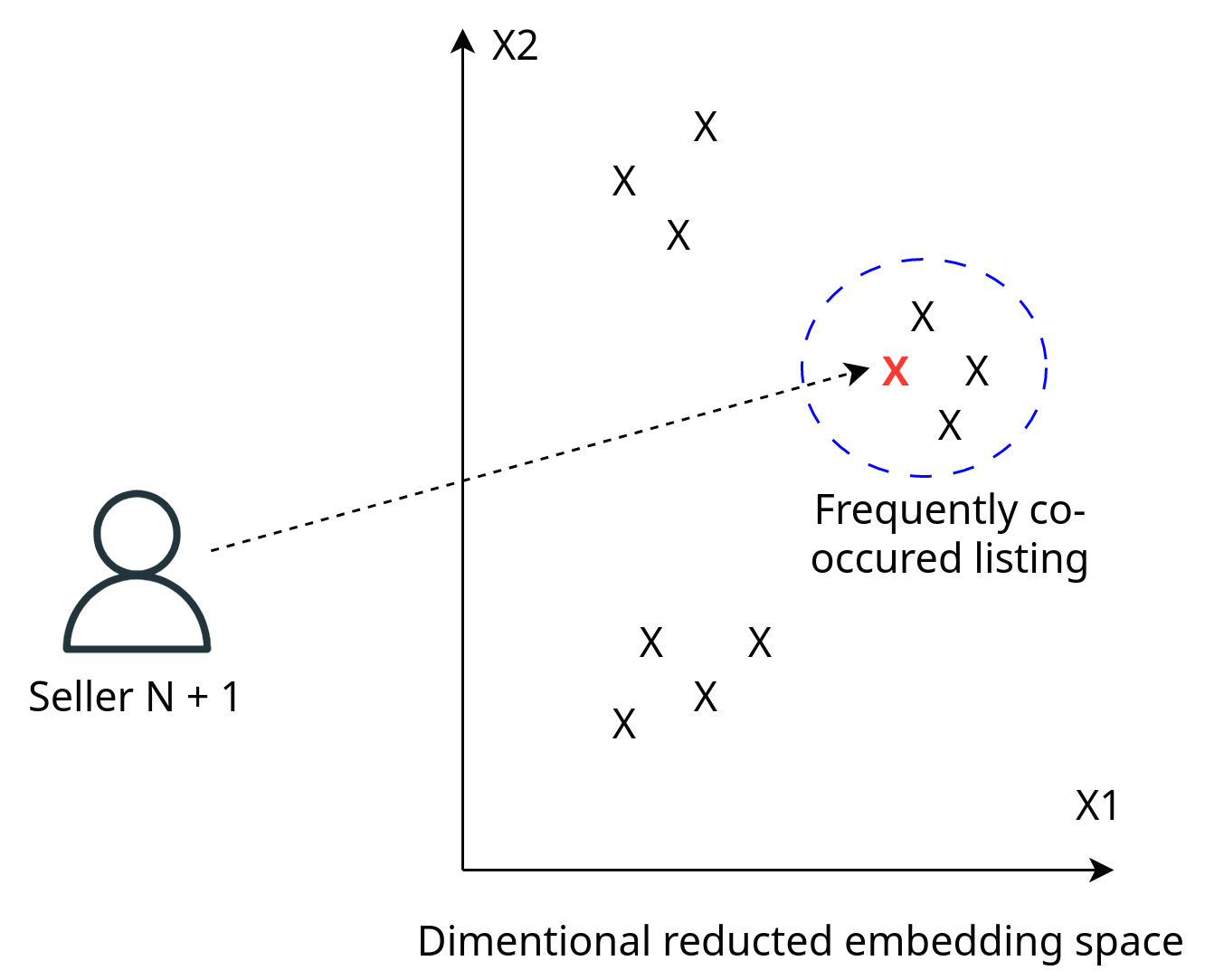
To implement this system, we train a model that maps each listing to an embedding vector. By doing so, if two listings frequently appear together in the buyer’s browsing history, their corresponding embedding vectors will be positioned closely in the embedding space. This proximity indicates a higher likelihood of similarity between the listings.
When recommending similar listings, our system searches the embedding space for listings that are closest to the ones currently being viewed. In Fig. 9, we illustrate this process by selecting the top 3 listings with the closest embeddings. One simple supervised learning algorithm that can be used for this task is the K-Nearest Neighbor (KNN) algorithm.
✅ Pros:
Timely recommendations.
▪ The algorithm focuses on the buyer's recent interactions, providing recommendations that align with their immediate preferences and increasing relevance and timeliness.
Personalization.
▪ By considering the buyer's browsing history, the algorithm generates personalized recommendations tailored to their preferences, enhancing the user experience.
Embedding space efficiency.
▪ Mapping listings to embedding vectors enables faster computation and retrieval of similar listings, improving system performance.
❌ Cons:
Limited long-term preferences.
▪ The algorithm may not fully capture the buyer's long-term interests or evolving preferences, potentially leading to less accurate recommendations over time.
Cold-start problem.
▪ New buyers or sellers with limited browsing history pose challenges for accurate recommendations due to insufficient data to establish patterns or similarities.
Dependency on browsing history.
▪ Sparse or incomplete browsing history may compromise the algorithm's performance and result in less accurate suggestions.
People You Might Know
This system is particularly useful when buyers are unsure of what they want but are interested in using the service. Its purpose is to connect individuals who share common interests and help them find mutually beneficial deals. Known as “People You May Know” (PYMK), it provides a list of users who you may want to connect with based on shared attributes such as location, personality traits, or commodity preferences. Major social platforms like Facebook, LinkedIn, and Twitter leverage the power of PYMK to enhance their software.
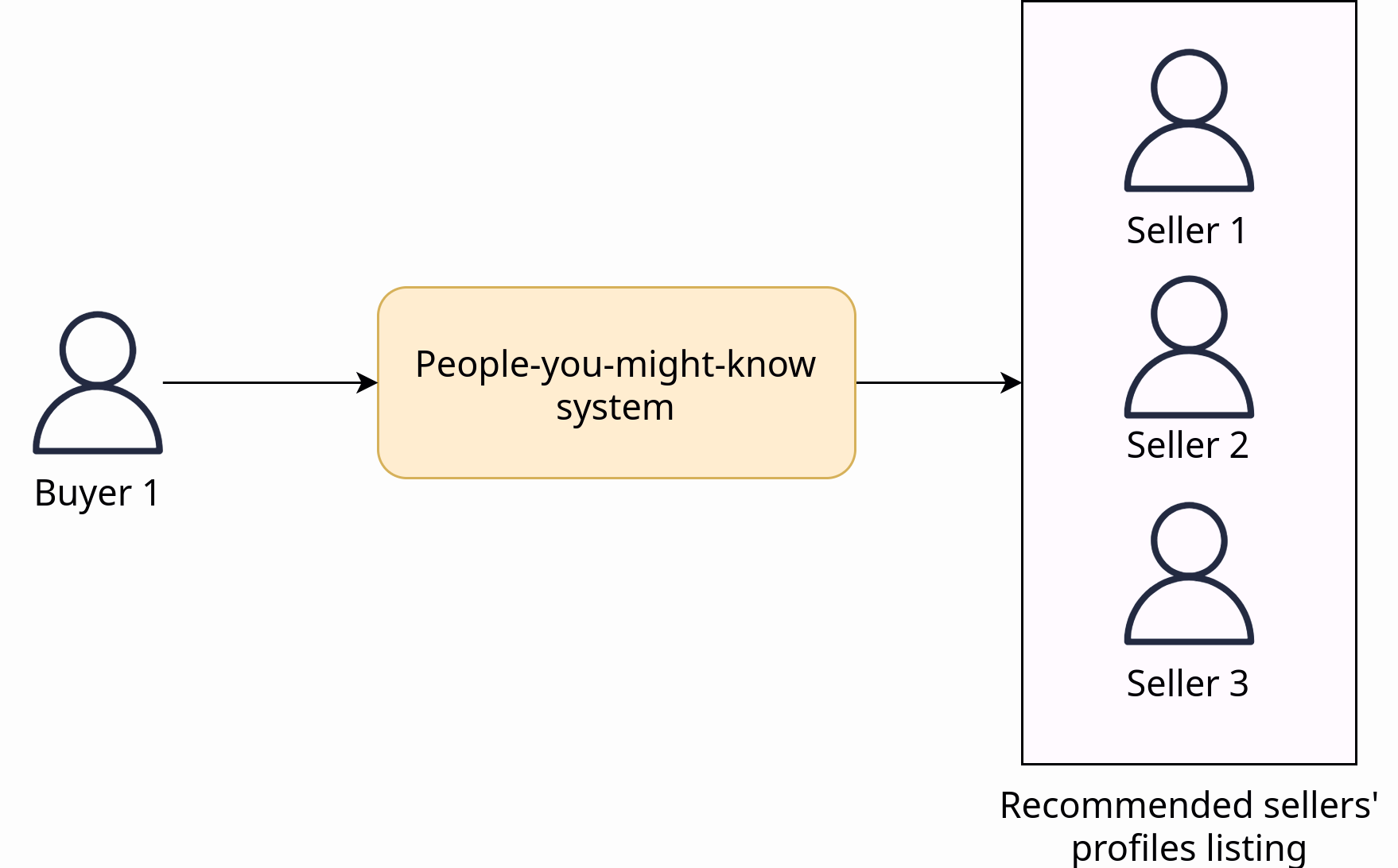
Assumptions: In the context of matching suitable sellers to buyers (or vice versa), we assume that there is a single commodity being handled by multiple sellers.
Framing problem as ML task: The primary objective is to maximize the number of strong connections between users. This entails identifying individuals who have compatible preferences and characteristics, increasing the likelihood of a successful match.
Data Collection: To collect personal information and preference data, both sellers and buyers are required to log in. This data can be gathered through filtering-tabs or questionnaires, which can be curated by the company’s commodity specialists. Additionally, companies may employ tools such as the Myers-Briggs Type Indicator (MBTI) to assess personality preferences and the Gallup Clifton Strengths assessment to understand individuals’ strengths or natural talents. The idea behind these assessments is that individuals with similar personality traits and complementary strengths are more likely to form meaningful connections. Here are examples of seller, buyer, and seller-buyer rating databases that can be utilized for data analysis and model training.



Matching Algorithms: In the PYMK system, there are two approaches that can be used: Pointwise Learning to Rank and Edge Prediction.
Pointwise Learning to Rank
In the Pointwise Learning to Rank (LTR) approach, we utilize a binary classification model that takes two user profiles as input and outputs the probabilities of connection strength between them.

✅ Pros:
Simplicity.
▪ LTR offers a straightforward binary classification model for assessing connection strength between users based on their profiles.
Privacy preservation.
▪ LTR's pairwise comparisons protect user privacy by not exposing detailed profiles.
Efficient computation.
▪ LTR's binary classification model is computationally efficient, making it suitable for large-scale systems.
❌ Cons:
Limited context.
▪ LTR may overlook the broader social context and interactions among users, potentially resulting in less accurate predictions. It doesn't capture network effects and community dynamics that influence connections.
Edge Prediction
The Edge Prediction approach is commonly used in social media platforms as it encourages users to build larger networks. As we are not trying to build a social network, this approach might not be suitable for our SaaS. In this approach, we enhance the model by incorporating graph information. This allows the model to leverage additional knowledge extracted from the social graph to predict the existence of an edge (connection) between two nodes (users). It’s important to note that the graph represents the relationships or edges between nodes, capturing the connections between users in the system.
✅ Pros:
Social context.
▪ Edge Prediction leverages graph information to consider social connections, enhancing the accuracy of recommendations by capturing network effects and community dynamics.
Enhanced recommendations.
▪ Edge Prediction provides more personalized and meaningful recommendations, leading to stronger connections and user satisfaction.
Scalability.
▪ Edge Prediction scales well for large-scale social graphs, allowing for efficient processing.
❌ Cons:
Increased complexity.
▪ Integrating graph information adds complexity, requiring additional computational resources and algorithmic considerations.
Data sparsity.
▪ Edge Prediction may struggle with sparse data or limited connections, leading to less accurate predictions for users with fewer network connections.
Chatbot
Slow customer support is a common challenge that can be addressed effectively through the integration of chatbots. These automated systems can reduce manual labor while providing quick assistance to meet buyer’s needs.

Assumptions: Although slow customer support is not inherently an ML problem, optimizing the response time lies in routing buyer requests to the appropriate seller. This can be framed as a multi-class classification problem, where the objective is to classify and route requests accurately.
Framing problem as ML task: Slow customer support is a problem but it is not an ML problem as there is no obvious objective function to optimize. The bottleneck here is the responding to buyer’s requests lies in routing the request to the right seller. Thus, this is a multi-class classification problem.
Data Collection: Data can be collected through filtering-tabs or chatbot questionnaires, leveraging the interaction between buyers and the chatbot. Advanced pretrained natural language processing (NLP) models can be used to extract relevant features from the customer conversations.
Matching Algorithm: To address the routing challenge, a combination of NLP techniques, text processing, and feature extraction can be employed. For multi-class classification, lightweight algorithms like Decision Trees can be utilized. Alternatively, deep learning models such as pretrained BERT can be employed for more complex conversation and text classification tasks.
✅ Pros:
Enhanced customer support.
▪ Chatbots provide quick and automated assistance, improving the overall customer support experience.
Reduced manual labor.
▪ Chatbots reduce the need for manual communication, freeing up resources for other tasks.
Data-driven personalization.
▪ Chatbots collect and analyze data to offer personalized recommendations and responses.
Advanced NLP capabilities.
▪ Pretrained NLP models enable accurate feature extraction and understanding of customer conversations.
❌ Cons:
Lack of human interaction.
▪ Some buyers may prefer the human touch and empathy that chatbots may lack.
Limited contextual understanding.
▪ Complex or nuanced customer requests may pose challenges for chatbots in understanding and providing appropriate responses.
Initial development and training effort.
▪ Building and training chatbot systems, especially with advanced models, requires significant upfront investment.
Potential misinterpretation of intent.
▪ Chatbots may occasionally misinterpret buyer queries, leading to incorrect responses or routing to inappropriate sellers.
Citation
Cited as:
Nguyen, Minh. (May 2023). Machine Learning for Profile-Matching System https://mnguyen0226.github.io/posts/profile_matching/post/
Or
@article{nguyen2023mlpm,
title = "Machine Learning for Profile-Matching System",
author = "Nguyen, Minh",
journal = "mnguyen0226.github.io",
year = "2023",
month = "May",
url = "https://mnguyen0226.github.io/posts/profile_matching/post/"
}
References
[1] C. Huyen, Designing Machine Learning Systems. Beijing: O’Reilly, 2022.
[2] Amplitude, “Amplitude apis,” Amplitude Developer Center, https://www.docs.developers.amplitude.com/analytics/apis/ (accessed May 28, 2023).
[3] MozDevNet, “Intersection observer API - web apis: MDN,” Web APIs | MDN, https://developer.mozilla.org/en-US/docs/Web/API/Intersection_Observer_API (accessed May 28, 2023).
[4] “The Elk Stack: From the creators of Elasticsearch,” Elastic, https://www.elastic.co/what-is/elk-stack (accessed May 28, 2023).
[5] “Optimizing people you may know (PYMK) for Equity in Network Creation,” LinkedIn Engineering, https://engineering.linkedin.com/blog/2021/optimizing-pymk-for-equity-in-network-creation (accessed May 28, 2023).
[6] “Serving a billion personalized news feeds,” YouTube, https://youtu.be/Xpx5RYNTQvg?t=1823 (accessed May 28, 2023).
[7] M. Grbovic, “Listing embeddings in search ranking,” Medium, https://medium.com/airbnb-engineering/listing-embeddings-for-similar-listing-recommendations-and-real-time-personalization-in-search-601172f7603e (accessed May 28, 2023).
[8] “Powered by AI: Instagram’s explore recommender system,” Meta AI, https://ai.facebook.com/blog/powered-by-ai-instagrams-explore-recommender-system (accessed May 28, 2023).
[9] Deep Neural Networks for YouTube recommendations, https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf (accessed May 28, 2023).
[10] C. Goodrow, “On YouTube’s recommendation system,” blog.youtube, https://blog.youtube/inside-youtube/on-youtubes-recommendation-system/ (accessed May 28, 2023).
